비지도학습중 군집화 모델인
K-means clustering에 대해서 알아보자
군집화 모델
군집화 모델이란 데이터를 비슷한 그룹(클러스터)끼리 나누는 기법이다.
비슷한 특성을 가진 데이터를 같은 클러스터로 묶어서 그 값들이 비슷한 특성을 가지고,
결과적으로는 클러스터끼리의 차이를 만들어 유의미한 분류를 해낸다.
K-means clustering
K-menas clustering이란?
K-menas clustering은 데이터의 포인트위치에 따라서 가까운 데이터포인트들끼리 묶이며 클러스터를 생성하는 것이다.

위의 사진과 같이, 데이터포인트들의 위치에 따라서, 시작 클러스터를 기준으로 가까이에 있는 데이터포인트를
자신의 클러스터에 끌어들이고 그렇게 갱신된 클러스터의 중심에 가장 가까운 데이터포인트를 다기 포함시킨다.
단계
k-means clustering의 단계는 총 4단계로 나눠진다.
- 설정? 초기화 : 사용자가 k의 값을 넣어 일정한 수 만큼의 클러스터를 생성 시킬 수 있다.
- 할당 하기 : 데이터 포인트들의 중심을 클러스터의 중심으로 할당한다.
- 업데이트 : 클러스터의 중심을 기준으로 클러스터에 속한 모든 데이터의 평균으로 중심을 업데이트한다.
- 반복 : 모든 데이터 포인트가 클러스터에 포함이 될때까지 모든 과정을 반복한다.
k-means clustering의 독특한 점이라고 한다면,
사용자가 클러스터의 갯수를 지정해 줘야 한다는점이다.
결국 그렇다는것은, k에 대입되는 숫자에 따라서 분류의 결과가 차이가 많이 날 수 밖에 없다는 것이다.
거리 측정 방법
클러스터에서 다른 데이터 포인트를 할당시킬때, 클러스터의 중심으로 부터 가장 가까운 데이터 포인트를
가져온다고 했다. 저 표는 시각화 한 것으로 실제로 저렇게 나열되 있지 않기 때문에, 우리는 그 거리를 측정해야 한다.
거리의 측정 방법으로는 유클리드 거리를 사용하여서 데이터 포인트와 군집중심 즉 클러스터의 중심 간의 거리를
계산할 수 있다.
엘보우 방법
위에서 말했듯이, 유저의 k값에 따라서 모델의 성능이 좌우되기 때문에,
K의 값이 매우 중요하다.
하지만 엘보우 방법을 사용하면 최적의 k 의 값을 알아 낼 수 있다.
k값을 점점 증가시키면서 클러스터의 응집도를 계산하고 이에 가장 급격히 응집도가 감소하는 지점
즉 최적의 클러스터의 수를 나타낸다. 즉 최적의 k값을 나타낸다고 볼 수 있다.
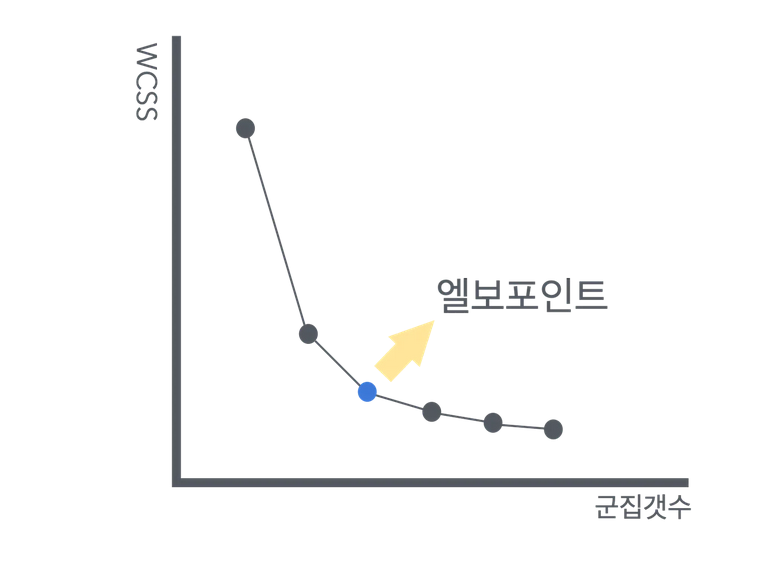
이런 그래프의 형식을 띄고 있어 엘보우 방법이라고 한다.
실습
사실 강의를 참고로 코드를 적었기 때문에
잘모르겠다.
k-means_clustering.ipynb - Colab
k-means_clustering.ipynb
Run, share, and edit Python notebooks
colab.research.google.com
끝
'용어정리 > Machine-Learning' 카테고리의 다른 글
| Machine-Learning 용어정리 (DBSCAN) (0) | 2024.10.23 |
|---|---|
| Machine-Learning 용어정리 (계층적 군집화) (0) | 2024.10.23 |
| Machine-Learning 용어정리 (SVM, KNN, 나이브베이즈, 의사결정나무) ver 2 (1) | 2024.10.23 |
| Machine-Learning 용어정리 (데이터셋) (3) | 2024.10.22 |
| Machin-Learning 용어정리 (로지스틱 회귀) (0) | 2024.10.21 |