딥러닝
신경망의 기본 원리에 대해서 알아보자
퍼셉트론
딥러닝에서는 인간의 뇌를 본떠 인공신경망을 만들었다. 이때 우리의 뇌의 뉴런과 같이 딥러닝의 인공 신경망에도
퍼셉트론이라는 것이 있다.
이는 인공 신경망에서 가장 기본적인 단위로 쓰인다.
이 퍼셉트론은 입력값을 받게 되면, 가중치인 W(weight)를 곱하고 이를 모두 더하여 활성화 함수를 통해서
출력값을 결정하게 된다.
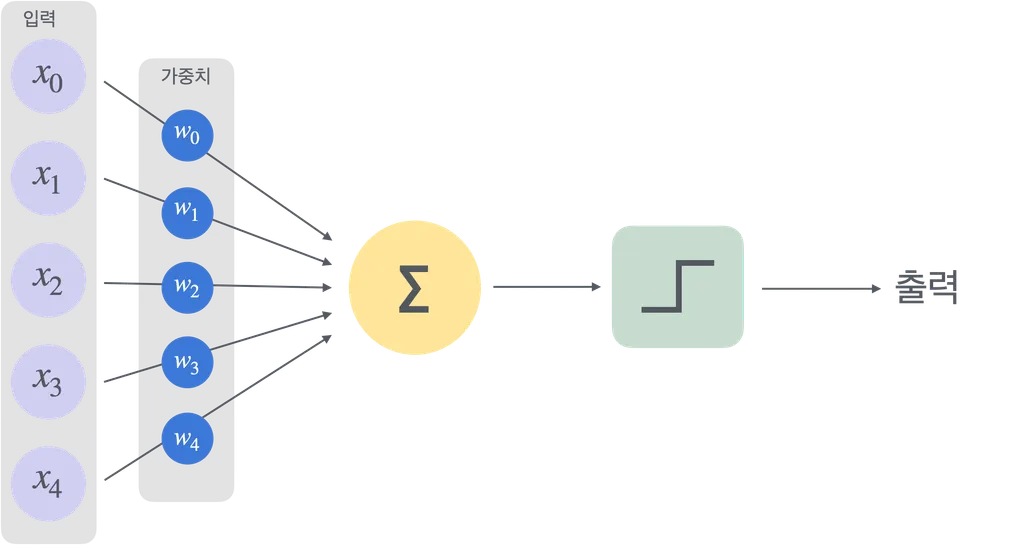
위의 사진이 퍼셉트론이며, 입력값과 가중치를 받아 계산한 후 활성화 함수를 사용하여 출력을 하는
일련의 플로우를 표현한 것이다.
(수학식은 패스)
다층 퍼셉트론
이전의 글인 딥러닝의 기본개념에서 우리는 딥러닝의 인공 신경망이 다층으로 되어 있다고 했다.
이는 다층 퍼셉트론인 MLP(Multi-Layer Perceptron)의 개념이다.
이들은 입력층, 은닉층, 출력층으로 나뉘어져 작동을 한다.
레이어의 개념
위에서 설명한 층들은 Layer라고 한다.

위의 사진처럼 레이어가 나뉘어져 있다.
입력 레이어
입력 레이어는 외부의 데이터가 인공 신경망에 들어올 때 입력이 되는 부분이다.
입력레이어 에서의 뉴런의 갯수는 입력한 데이터의 수와 동일하다.
은닉 레이어
은닉 레이어는 입력 레이어와 출력 레이어의 사이에 존재한다.
이는 입력 데이터에서 데이터를 전송받아 데이터의 특징을 추출하고 학습하는 부분이다.
뉴런수와 층수에 따라서 모델의 복잡성과 성능에 큰 영향을 미친다.
출력 레이어
출력 레이어에서는 신경망의 마지막 부분으로, 은닉 레이어를 통해 최종 값을 예측하여 출력하는 부분이다.
이때, 출력 레이어의 뉴런수는 예측하려고 하는 클래스의 수와 그 출력 차원이 동일하다.
XOR과 MLP
구형의 단일 퍼셉트론은 선형 분류만 할 수 있기 때문에, 과거의 딥러닝에서는 일차원적 즉 선형의 문제만 풀 수 있었다.
XOR문제 같은 경우는 두 입력값을 받아 값의 차이가 있을때만 1을 출력을 하는 문제 이기 때문에, 단일 퍼셉트론으로는
해결할 수 없었던 것이다.
하지만 MLP즉 다층 퍼셉트론으로 인하여, XOR문제도 해결을 할 수 있게 되었다.
활성화 함수
활성화 함수란 퍼셉트론의 예시 사진에서 설명했듯이, 입력받은 데이터와 가중치를 계산한 값을 받아서
출력값으로 변환을 하는 역할을 한다. 이는 신경망에서 각 뉴런에게 받은 값들을 출력값으로 변환한다는 것이다.
위에서 설명하듯 MLP.또한 이러한 활성화 함수가 있어야 가능하며, 활성화 함수가 존재하지 않는다면 선형변형만
할 수밖에 없다. 즉 선형 머신러닝과 다를게 없어진다는 것이다.
활성화 함수의 종류
ReLU
Rectified Linear Unit의 약자이다.
렐루 함수라고도 하는데 이는 활성화 함수에서 가장 많이 쓰이는 함수 중 하나이다.
음수를 0으로 변경하고, 양수는 그대로 두는 함수이다.

위의 사진처럼 음수인 경우에는 0을 반환하고, 양수인 경우에는 선형적으로 증가한다.
계산이 간단하지만, 값이 음수이면 죽은 뉴런문제가 생길 수 있다.
Sigmoid
시그모이드 함수는 숫자값을 0과 1 사이로 변환을 한다.

위의 사진처럼 곡선인 s자의 형태로 상승한다.
출력값이 확률처럼 해석이 될 수 있다는 장점이 있지만,
값이 매우 작거나 기울기가 0에 가까울 경우에는 학습이 잘 안 되는 문제
즉 기울기의 소실 문제가 발생 할 수 있다.
Tanh
Hyperbolic Tangent 즉 쌍곡 탄젠트 함수라고도 한다.
이는 출력 값을 -1과 1 사이로 변환을 한다.
모형의 자체는 시그모이드와 비슷하게 s자의 곡선이지만, 값의 범위가 -1부터 1이므로 조금 더 넓다고 할 수 있다.
시그모이드에 비해서 범위가 더 넓어서 데이터가 중심으로 모이는 효과가 줄어들고, 학습의 속도가 빨라진다.
하지만 여전히 기울기의 소실 문제가 발생할 수 있고, 입력값이 극단적 (매우 크거나 작거나) 이라면,
기울기가 0에 가까워져서 학습이 잘 안 되거나 멈추는 문제가 발생할 수 있다.
주로 0을 기준으로 대칭적인 출력이 필요할 때 쓰인다.
손실 함수
손실 함수(Loss Function)은 모델의 예측값과 실제값 사이의 차이를 측정하는 함수이다.
모델의 성능을 평가하고, 최적화 알고리즘을 통해서 모델을 좀더 상향되게 학습시키는데에 사용이 된다.
MSE
손실 함수의 종류중 하나이며, 회귀 문제에 주로 사용된다.
예측 값과 실제 값의 차이를 제곱하여 평균을 구한다.
요즘은 RMSE가 생겨 제곱한 값을 다시 루트하여 평균을 구하는 방식도 존재한다.
Cross-Entropy
손실 함수의 종류중 하나이며, 분류 문제에서 주로 사용된다.
예측 확률과 실제 클래스 간의 차이를 측정한다.
최적화 알고리즘
최적화 알고리즘이란, 손실함수로 평가한 모델을 좀더 좋은 방향으로 학습을 시키게 하는 알고리즘이다.
SGD
Stochastic Gradient Descent의 약자이다.
무작위의 선택된 데이터를 사용하여 기울기를 계산하고, 가중치를 업데이트 시키며 학습시킨다.
계산이 빠르고, 큰 데이터셋에도 유용하게 사용된다.
최적점에 도달하기까지 진동, 즉 오차가 위아래로 튈 수 있다.
Adam
Adaptive Moment Estimation의 약자이다.
모멘텀과 RMSProp을 결합한 알고리즘으로 학습률을 적응적으로 조정한다.
빠른 속도와 안정적인 학습을 가능하게 한다.
하이퍼파라미터가 복잡해질 수 있다.
역전파
역전파는 신경망의 가중치를 학습 시키기위한 알고리즘이다.
출력에서 입력방향 즉 역방향으로 손실함수의 기울기를 계산해 가중치를 업데이트 시킨다.
'용어정리 > Deep-Learning' 카테고리의 다른 글
| Deep-Learning 용어정리 (Attention) (0) | 2024.10.29 |
|---|---|
| Deep-Learning 용어정리 (RNN) (0) | 2024.10.29 |
| Deep-Learning 용어정리 (CNN) (0) | 2024.10.29 |
| Deep-Learning 용어정리 (인공 신경망) (0) | 2024.10.28 |
| Deep-Learning 용어정리 (딥러닝) (4) | 2024.10.25 |